输出内容不够专业,无法精准匹配行业业务场景需求 对企业内部知识库、业务资料理解浅薄,常出现答非所问 核心业务数据高度敏感,不敢上传云端进行模型微调 微调依赖人工标注、复杂调参,不仅成本高昂,更难以实现持续迭代 如果以上痛点正中你的困扰,这款全自动“训练数据集生成+微调训练”一体化智能工具,正是你补齐大模型应用短板、释放AI价值的关键拼图——让通用大模型,彻底变身懂你业务的“专属赋能模型”。 这款一体化智能软件工具,专为已部署大模型、但希望进一步提升应用效果的企业用户量身打造,通过全自动化流程打通“数据处理-模型微调-持续迭代”全链路,大幅降低企业使用门槛与运营成本。 ZHIYA 操作极简,用户仅需完成两步准备,后续全流程交由系统自动完成: 准备企业自有原始文本资料(含文档、内部知识库、业务资料等) 准备好算力环境。 自动处理原始资料,生成符合行业标准的高质量微调训练数据集 通过智能化微调算法,自动生成深度适配企业业务场景的垂类模型 仅需在原有系统中替换通用模型,新垂类模型即可直接上线启用 更关键的是,工具支持企业资料、知识体系的持续高频更新与微调,让模型紧跟业务发展节奏动态迭代,彻底告别“一次性训练即终止”的局限。工具以软件服务形式交付,开箱即用,大幅降低企业技术门槛与部署成本。 依托全自动数据集生成与智能化集约微调算法,工具从根源上颠覆传统微调模式,实现“降本增效”与“安全可控”的双重核心突破: 彻底摆脱对大规模人工标注的依赖 无需复杂人工调参,省去繁琐的工程配置流程 让“频繁微调、持续迭代”在成本层面完全可行,助力企业持续优化模型效果 无需人工介入标注:传统微调需人工处理数据标注、清洗,易导致敏感信息暴露;本工具通过自动化语义结构化与智能标注技术,全程无人工参与数据标注环节,从源头切断隐私泄露路径 支持本地私有化部署:整套工具与模型训练流程可部署于企业自有机房或私有云,数据全程不出内网,全流程在企业可控范围内完成,完全满足金融、政务等行业严格的数据安全与合规要求 ZHIYA 工具中全自动生成高质量微调数据集的技术框架与核心算法,核心源自《中文新闻语义结构化标注》国家标准。该标准虽初始面向新闻领域,但本质是一套适配中文通用场景的语义理解与结构化标注框架,可广泛适配各行业文本内容: 政策文件、规章制度 行业报告、专业文献 企业知识库、产品文档 客服对话记录、业务文本等 借助这套权威框架,系统可自动完成文本语义结构化、关键信息抽取与关系建模、高质量训练样本构建,为后续模型微调提供坚实、可靠的数据基础。 生成的数据集达到国内“可信AI”数据集质量最高的四级标准 (检验结果表) 微调后的垂类模型,在专业术语理解准确率、行业知识问答精准度、业务场景适配度等关键指标维度,均实现显著提升 ZHIYA 基于这套“全自动数据集生成+微调训练”一体化工具,我们成功打造了面向个人与组织的私域个性化模型智能助手——知芽。 “知芽”精准匹配私域AI使用需求, 核心优势鲜明: 深度理解企业内部知识与业务语言体系 依托持续更新的企业资料,不断迭代优化回答质量与适配能力 以安全、可控的私域部署方式,成为企业日常工作的高效AI助手 值得一提的是,“知芽”解决方案已成功入选“江苏省人工智能学会2025年度江苏省应用场景标杆项目”,这一荣誉从侧面印证了本工具在落地价值、技术成熟度与场景适用性上的行业领先水平。权威技术底座:源自国家标准,语义理解更精准

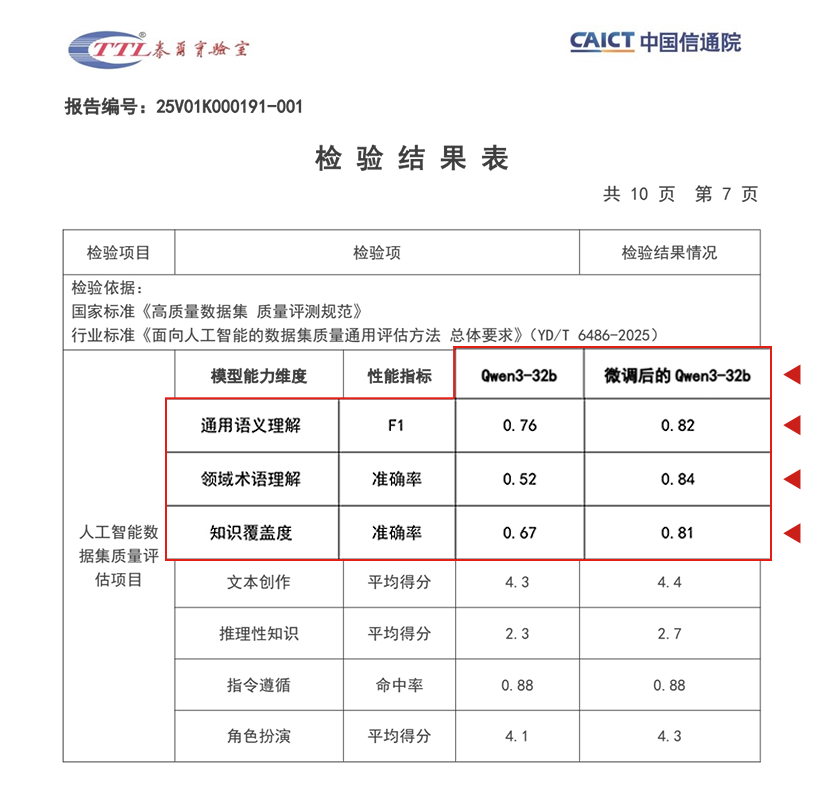
信通院权威测评:数据集与模型效果双达标、双优秀
工具自动生成的数据集及基于该数据集微调后的垂类模型,已通过中国信息通信研究院(信通院)权威测评,核心结果亮眼:

标杆落地:知芽——基于本工具打造的私域智能助手标杆


精准匹配:这四类用户,最适合使用本工具
已部署大模型,但效果不够“接地气”、业务适配度不足的企业
拥有海量行业文档、内部知识库,希望沉淀为“企业大脑”的组织
对数据安全、隐私合规要求严苛,需本地化、私有化部署的单位(如政务、金融、法律等行业)
希望通过模型持续迭代,实现AI能力与业务发展同步成长的团队
从通用大模型到专属业务赋能模型,只差一套全自动化“数据集生成+微调训练”一体化工具。告别繁琐操作、高昂成本与安全顾虑,让AI真正深度融入业务、助力企业成长,这款工具值得企业重点关注!
本产品全国范围招募合作伙伴,联系人:林先生 18901593555
